
一周前,我们上线了第一个云端科研智能体,写了篇文章记录,反响还不错。今天第二个来了。
在说它能干什么之前,我想先聊聊这个名字。
她是谁
罗莎琳德·富兰克林(Rosalind Franklin)是英国晶体学家,X射线衍射专家。1952年,她在伦敦国王学院拍下了"51号照片"——一张精确揭示DNA分子螺旋结构的X射线衍射图像。Watson和Crick在未经她同意的情况下看到了这张照片,据此建立了DNA双螺旋模型,并在1962年获得诺贝尔奖。富兰克林在1958年因卵巢癌去世,年仅37岁,从未等来那一刻。
这是生物学史上知名度最高的一次遗憾之一。一个人的数据,撑起了别人的荣誉,而她连争辩的时间都没有。
2026年4月,OpenAI发布GPT-Rosalind——一个专为生命科学研究工作流而建的前沿推理模型,用她的名字命名。X上立刻有人指出了讽刺:用一个"成果被封锁"的科学家命名,然后把这个模型锁起来只给特定机构用,名字里的遗憾在现实里重演了一遍。这个批评我觉得是成立的。
但不管怎样,名字本身是值得郑重对待的。我们在做第二个智能体的时候,决定用这个名字。

50个技能是什么
OpenAI发布GPT-Rosalind的同时,在GitHub上开源了一套生命科学研究插件,包含50余个模块化技能,分六个方向:遗传与变异证据(GWAS、ClinVar、gnomAD、FinnGen、UK Biobank等)、表达与功能基因组(Human Protein Atlas、CELLxGENE、ENCODE)、蛋白质结构与通路(AlphaFold、PDB、UniProt、STRING)、化学与药理(ChEMBL、PubChem、PharmGKB)、临床与转化(ClinicalTrials.gov、cBioPortal)、文献与文档(PubMed全家桶 + Word/PDF/Excel/PPT生成)。
这些技能不依赖GPT-Rosalind,配合任何主流大模型都能跑。我们把它们整合进云端智能体,开箱即用,底层调用Codex或Claude Code来执行,也支持直接交付文档格式的产出。
两分钟一份GLP-1研究报告
光说能干什么没意思,我更想让你看到它是怎么工作的。
今天记录一次真实的接单过程。
任务是这样的:
用户委托了一个课题——"近5年GLP-1受体激动剂用于肥胖症治疗的研发、临床试验与上市进展梳理",并明确要求:
- 聚焦2021年以来已获批或进入III期临床的药物,重点品种包括司美格鲁肽(Wegovy)、替尔泊肽(Zepbound)、利拉鲁肽(Saxenda)
- 证据来源:PubMed/PMC文献、ClinicalTrials.gov试验登记、ChEMBL/PubChem/PharmGKB药理信息、FDA/EMA官方数据
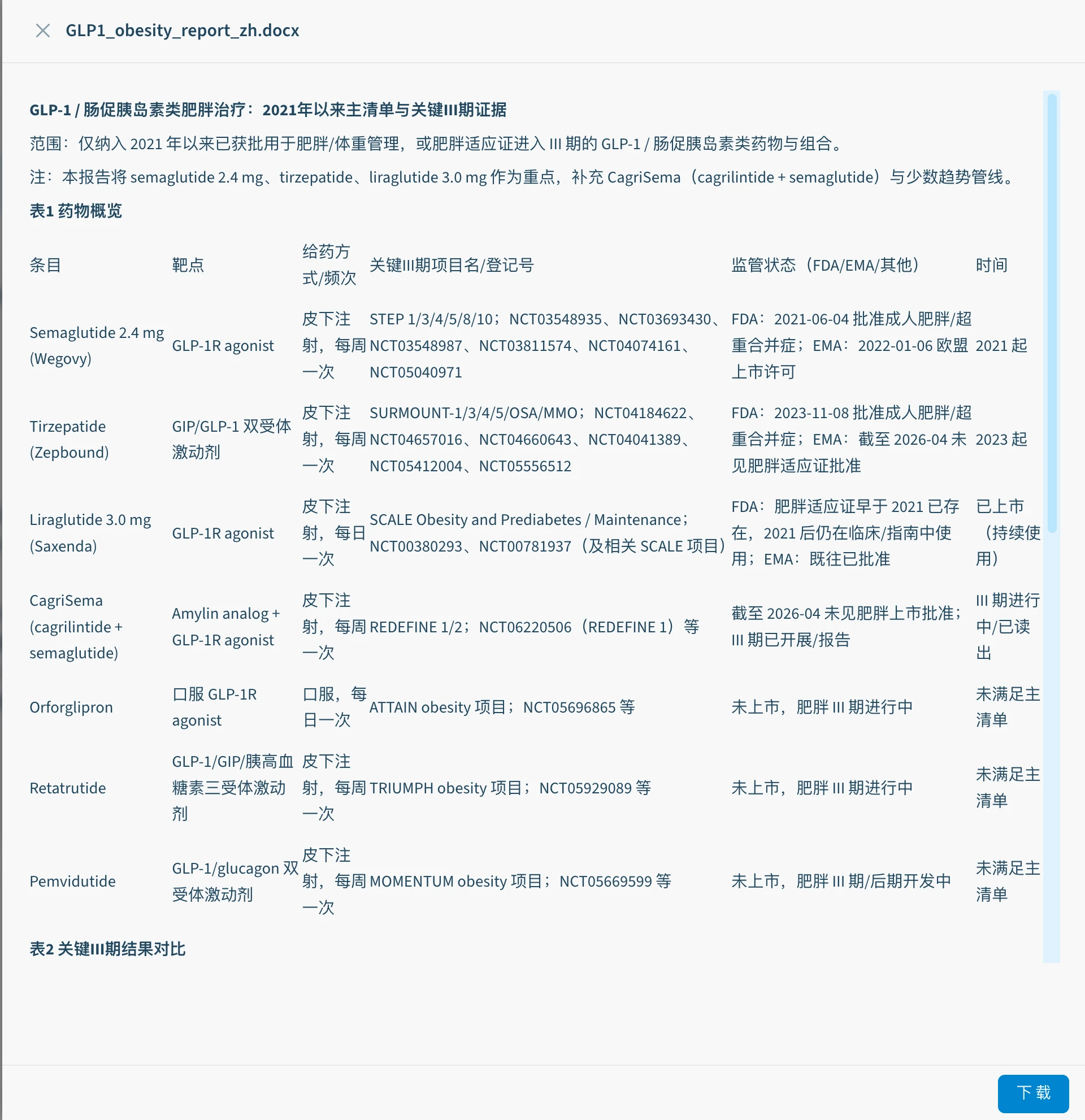
- 交付物:Word格式,包含两张核心对比表(药物概览表 + 临床试验结果对比表)、安全性分析、研发趋势、参考文献
这不是一个简单的问答,而是一份需要多数据源交叉验证的综述性报告委托。
罗莎琳德先和用户做了一轮确认,把研究边界对齐清楚:

罗莎琳德是怎么干的:
接到任务后,罗莎琳德用约14秒将用户的原始委托整理成一份精准的任务指令,交给底层执行引擎Codex——后者是一个能在沙盒环境中运行代码、调用工具、生成文件的执行系统。
Codex接单后,先说了一句"开工声明":确认任务、说明计划、给出预期产出路径。然后罗莎琳德再次细化了研究边界:主清单筛选标准、三个核心品种需要有试验登记号(NCT编号)和减重幅度数据、CagriSema的III期资质需要核实、三个趋势管线单列"下一代趋势"章节并明确注明不满足主清单条件、参考文献必须有PMID/DOI/NCT编号可验证。
这种"分层指挥"的结构很典型:协调层(罗莎琳德)负责把任务分解清楚,执行层(Codex)负责具体完成。
Codex随后开始工作。先检查了工作环境,确认目录为空、依赖库可用——相当于"打开抽屉确认文具到位"。然后生成了一段完整的Python脚本,调用python-docx构建Word文档:表1是7个药物的概览(含靶点机制、获批时间、临床试验系列);表2是各药物关键III期数据的横向对比(受试人群、疗程、主要终点、体重变化幅度、GI不良反应停药率)。
脚本写完立刻运行,文件生成后Codex做了自检:
ls -l GLP1_obesity_report_zh.docx
结果:文件确实生成,大小约39KB。
有一个小插曲:验证命令里用了 file 这个工具,沙盒里没有安装,报错退出。但Codex识别出这不影响核心产出,没有卡住,继续推进。这个小细节我觉得值得提——能不能识别出哪些错误是关键错误、哪些可以跳过继续,是系统容错能力的一个缩影。当然,我们会去继续完善运行环境。

最终交付:
Codex向罗莎琳德发出完成报告,内容包括:主清单限定执行到位(区分主清单品种与趋势管线)、三个重点品种均已覆盖关键III期试验及登记号、CagriSema的肥胖III期核实后纳入(REDEFINE 1,NCT06220506)、参考证据列表包含PMID/DOI/NCT编号和FDA/EMA时间节点。
罗莎琳德整理后推送给用户。
全程耗时:约2分钟3秒。 其中罗莎琳德的任务分发与汇总约26秒,Codex的实际研究与写作约87秒。消耗约200K token。
报告预览如下:
需要说明的是:这份报告是"有证据锚点的高质量初稿",不是"可以直接投稿的综述"。Codex的检索本质上还是整合自身知识库,时效性和精确度仍需用户二次核查。这个边界,我们会在智能体说明里写清楚。
现在能用了
Rosalind智能体现在已经上线,开箱即用,不需要配环境、不需要管API key,打开浏览器就能开始。
如果你是做生命科学研究的,或者有快速梳理某个领域进展、生成综述性文档的需求,欢迎来试试。也欢迎来报错,有积分奖励——真的,报错也是贡献。
接下来我们会继续迭代,技能覆盖会扩展,执行质量会提升,也会陆续推出针对更多场景的智能体。科研的每个环节都有值得做的事,我们不想做一个"什么都会、什么都不精"的大而全工具,更想在每个具体场景里做到真的好用。
关于麦伴聊斋
这是麦伴科研(MaltSci)记录产品研发进展的专栏,也是我们 build in public 的一个实践。我们在这里聊做产品的过程、走过的弯路、遇到的真实问题——不只是结果,也包括过程里的困惑和教训。如果你是在做科研的研究者,或者对科研 AI 感兴趣、自己也在摸索 AI 工具,欢迎一起来成长。